Parallel external memory
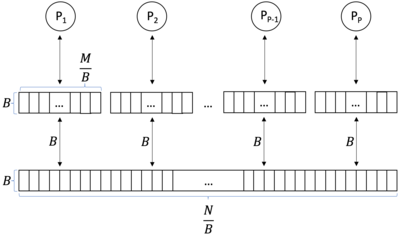
In computer science, a parallel external memory (PEM) model is a cache-aware, external-memory abstract machine.[1] It is the parallel-computing analogy to the single-processor external memory (EM) model. In a similar way, it is the cache-aware analogy to the parallel random-access machine (PRAM). The PEM model consists of a number of processors, together with their respective private caches and a shared main memory.
Model
Definition
The PEM model[1] is a combination of the EM model and the PRAM model. The PEM model is a computation model which consists of processors and a two-level memory hierarchy. This memory hierarchy consists of a large external memory (main memory) of size and small internal memories (caches). The processors share the main memory. Each cache is exclusive to a single processor. A processor can't access another’s cache. The caches have a size which is partitioned in blocks of size . The processors can only perform operations on data which are in their cache. The data can be transferred between the main memory and the cache in blocks of size .




I/O complexity
The complexity measure of the PEM model is the I/O complexity,[1] which determines the number of parallel blocks transfers between the main memory and the cache. During a parallel block transfer each processor can transfer a block. So if processors load parallelly a data block of size form the main memory into their caches, it is considered as an I/O complexity of not . A program in the PEM model should minimize the data transfer between main memory and caches and operate as much as possible on the data in the caches.


Read/write conflicts
In the PEM model, there is no direct communication network between the P processors. The processors have to communicate indirectly over the main memory. If multiple processors try to access the same block in main memory concurrently read/write conflicts[1] occur. Like in the PRAM model, three different variations of this problem are considered:
- Concurrent Read Concurrent Write (CRCW): The same block in main memory can be read and written by multiple processors concurrently.
- Concurrent Read Exclusive Write (CREW): The same block in main memory can be read by multiple processors concurrently. Only one processor can write to a block at a time.
- Exclusive Read Exclusive Write (EREW): The same block in main memory cannot be read or written by multiple processors concurrently. Only one processor can access a block at a time.
The following two algorithms[1] solve the CREW and EREW problem if processors write to the same block simultaneously. A first approach is to serialize the write operations. Only one processor after the other writes to the block. This results in a total of parallel block transfers. A second approach needs parallel block transfers and an additional block for each processor. The main idea is to schedule the write operations in a binary tree fashion and gradually combine the data into a single block. In the first round processors combine their blocks into blocks. Then processors combine the blocks into . This procedure is continued until all the data is combined in one block.




Comparison to other models
| Model | Multi-core | Cache-aware |
|---|---|---|
| Random-access machine (RAM) | No | No |
| Parallel random-access machine (PRAM) | Yes | No |
| External memory (EM) | No | Yes |
| Parallel external memory (PEM) | Yes | Yes |
Examples
Multiway partitioning
Let be a vector of d-1 pivots sorted in increasing order. Let A be an unordered set of N elements. A d-way partition[1] of A is a set , where and for . is called the i-th bucket. The number of elements in is greater than and smaller than . In the following algorithm[1] the input is partitioned into N/P-sized contiguous segments in main memory. The processor i primarily works on the segment . The multiway partitioning algorithm (PEM_DIST_SORT[1]) uses a PEM prefix sum algorithm[1] to calculate the prefix sum with the optimal I/O complexity. This algorithm simulates an optimal PRAM prefix sum algorithm.











// Compute parallelly a d-way partition on the data segments for each processor i in parallel do Read the vector of pivots M into the cache. Partition into d buckets and let vector be the number of items in each bucket. end for Run PEM prefix sum on the set of vectors simultaneously. // Use the prefix sum vector to compute the final partition for each processor i in parallel do Write elements into memory locations offset appropriately by and . end for Using the prefix sums stored in the last processor P calculates the vector B of bucket sizes and returns it.





If the vector of pivots M and the input set A are located in contiguous memory, then the d-way partitioning problem can be solved in the PEM model with I/O complexity. The content of the final buckets have to be located in contiguous memory.


Selection
The selection problem is about finding the k-th smallest item in an unordered list A of size N. The following code[1] makes use of PRAMSORT which is a PRAM optimal sorting algorithm which runs in , and SELECT, which is a cache optimal single-processor selection algorithm.

if then return end if //Find median of each for each processor i in parallel do end for // Sort medians // Partition around median of medians if then return else return end if


![{\displaystyle A[k]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/37bea76700f1268910c4be5ca16ef0f9193b40a1)




![{\displaystyle {\texttt {PEMSELECT}}(A[1:t],P,k)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c39d5a07ede4bdd5385f2ef30b08f53ecab830f9)
![{\displaystyle {\texttt {PEMSELECT}}(A[t+1:N],P,k-t)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/21685a86e7d03a3937c6ba2cf95c1724967d4d4e)
Under the assumption that the input is stored in contiguous memory, PEMSELECT has an I/O complexity of:

Distribution sort
Distribution sort partitions an input list A of size N into d disjoint buckets of similar size. Every bucket is then sorted recursively and the results are combined into a fully sorted list.
If the task is delegated to a cache-optimal single-processor sorting algorithm.

Otherwise the following algorithm[1] is used:
// Sample elements from A for each processor i in parallel do if then Load in M-sized pages and sort pages individually else Load and sort as single page end if Pick every 'th element from each sorted memory page into contiguous vector of samples end for in parallel do Combine vectors into a single contiguous vector Make copies of : end do // Find pivots for to in parallel do end for Pack pivots in contiguous array // Partition Aaround pivots into buckets // Recursively sort buckets for to in parallel do recursively call on bucket jof size using processors responsible for elements in bucket j end for










![{\displaystyle {\mathcal {M}}[j]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a79e9f6b98434837054f3ce301a6a283c09c904d)

![{\displaystyle {\mathcal {M}}[j]={\texttt {PEMSELECT}}({\mathcal {R}}_{i},{\tfrac {P}{\sqrt {d}}},{\tfrac {j\cdot 4N}{d}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/71b090408c8e1eefe120ea73f20112f89ba45305)


![{\displaystyle {\mathcal {B}}={\texttt {PEMMULTIPARTITION}}(A[1:N],{\mathcal {M}},{\sqrt {d}},P)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ee71380bf87811d22672bf62a50d5d9844891634)


![{\displaystyle {\mathcal {B}}[j]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/15afe12fdc196264ed086fccdd186ba470fcdcae)
![{\displaystyle O\left(\left\lceil {\tfrac {{\mathcal {B}}[j]}{N/P}}\right\rceil \right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/42f0326dc968b44303f83dccb1bd793dda7e41d9)
The I/O complexity of PEMDISTSORT is:

where

If the number of processors is chosen that and the I/O complexity is then:



Other PEM algorithms
| PEM Algorithm | I/O complexity | Constraints |
|---|---|---|
| Mergesort[1] | ||
| List ranking[2] | ||
| Euler tour[2] | ||
| Expression tree evaluation[2] | ||
| Finding a MST[2] |







Where is the time it takes to sort N items with P processors in the PEM model.

See also
- Parallel random-access machine (PRAM)
- Random-access machine (RAM)
- External memory (EM)
References
- ^ a b c d e f g h i j k l Arge, Lars; Goodrich, Michael T.; Nelson, Michael; Sitchinava, Nodari (2008). "Fundamental parallel algorithms for private-cache chip multiprocessors". Proceedings of the twentieth annual symposium on Parallelism in algorithms and architectures. New York, New York, USA: ACM Press. pp. 197–206. doi:10.1145/1378533.1378573. ISBN 9781595939739. S2CID 11067041.
- ^ a b c d Arge, Lars; Goodrich, Michael T.; Sitchinava, Nodari (2010). "Parallel external memory graph algorithms". 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS). IEEE. pp. 1–11. doi:10.1109/ipdps.2010.5470440. ISBN 9781424464425. S2CID 587572.
- v
- t
- e
- Temporal
- Simultaneous (SMT)
- Simultaneous and heterogenous
- Speculative (SpMT)
- Preemptive
- Cooperative
- Clustered multi-thread (CMT)
- Hardware scout
- Process
- Thread
- Fiber
- Instruction window
- Array
- Multiprocessing
- Memory coherence
- Cache coherence
- Cache invalidation
- Barrier
- Synchronization
- Application checkpointing
 Category: Parallel computing
Category: Parallel computing













